
티스토리 뷰
Abstract
- Mixtral 8x7B는 Sparse Mixture of Experts(SMoE) 언어 모델이다.
- Mistral 7B와 같은 아키텍처이며 각 레이어는 8개의 Feedforward blocks(experts)로 구성된다.
- 모든 토큰은 각 레이어에서 router network가 선택한 두 개의 expert와 결합된다.
- 선택된 expert는 각 timestep에서 다를 수 있다.
- 결론적으로 각 토큰은 47B 파라미터에 접근할 수 있지만, 추론(inference)에서 13B의 active parameters만 사용한다.
- context size는 32k 토큰으로 훈련되었다.
- Llama2 70B, GPT-3.5로 벤치마크 성능을 평가했고, 특히 수학, 코드 생성 부분에서 Llama2 70B보다 뛰어났다.
- Mixtral 8x7B – Instruct은 instructions을 따르도록 Fine-tune했고 채팅모델 human bench marks에서 GPT-3.5 Turbo, Claude-2.1, Gemini Pro, and Llama 2 70B보다 우수하다.
1 Introduction
Mixtral 8x7B은 Sparse Mixture of Experts model (SMoE) 사용하여 작은 배치 크기에서 빠른 추론 속도, 큰 배치 크기에서는 많은 처리가 가능하다.
Mixtral은 SMoE 네트워크가 적용됐다. feedforward 블럭의 8개의 파라미터 집합에서 선택하는 decoder-only model이다. 매 레이어에서 토큰은 라우터 네트워크가 선택한 두 개의 그룹(expert)와 결합하고 추가적으로 결합한다. 모델이 파라미터의 일부 set만 사용하는 기술로 모델 전체 파라미터 수는 증가하지만 처리 비용과 지연율을 조절할 수 있다.
Mixtral은 context size는 32k 토큰이며, 다국어 데이터를 이용해 사전학습되었다. 수학, 코드 생성, 다국어 이해 task에서 Llama 2 70B보다 뛰어나다. 또한 32k 토큰의 context window로 입력된 문장(sequence)의 길이와 문장에서 찾을 정보의 위치(location)에 무관하게 정보를 탐색할 수 있다.
Mixtral 8x7B – Instruct는 supervised fine-tuning(SFT)와 Direct Preference Optimization(DPO) 방식을 적용하여 instrutions을 따르는 채팅 모델로 파인튜닝했다. GPT-3.5 Turbo, Claude-2.1, Gemini Pro, and Llama 2 70B보다 채팅 모델 human evaluation 벤치마크에서 뛰어났다. 또한 편견(bias)이 적고, 균형적인 감정(balanced sentiment)을 BBQ, BOLD 벤치마크로 확인했다.
2 Architectural details
Mixtral은 transformer 아키텍처 기반이다. Mixtral은 fully dense context length of 32k tokens를 지원한다. 즉 아키텍처 파라미터에 작성된 32768개의 토큰이 input으로 들어올 수 있고, 토큰의 정보가 공유된다(fully dense). feedforward block들은 Mixture-of-Expert layer들로 교체됐다.
2.1 Sparse Mixture of Experts

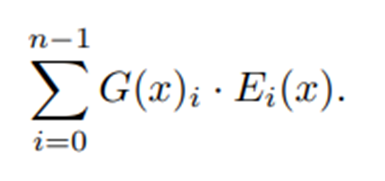
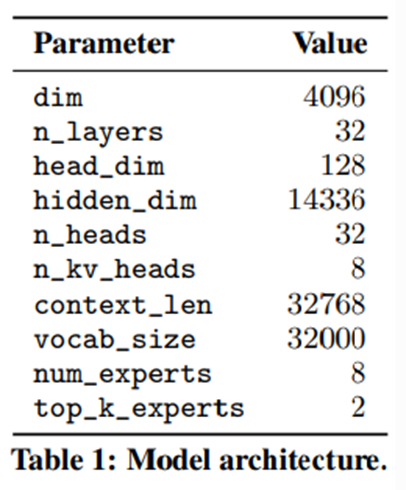
Mixture of Experts layer의 input $x$에 대한 output은 expert network의 output의 가중합에 의해 결정된다. expert network의 가중치 weights는 gating network에 의해 결정된다. $G(x)_i$는 expert에 대한 $n$-차원의 출력으로 나타낸다. $E_i(x)$는 $i$번째 expert network의 output이다. gating vector가 분리되었기 (sparse) 때문에 expert가 gate와 연산과정에서 0이 되지 않는다.

$G(x)$는 linear layer의 Top-K logit에 softmax를 취한다. K는 토큰당 사용된 expert의 수로 하이퍼파라미터이다. 모델 아키텍처의 표에 top_k_experts는 2로 정의되었다. 사용된 expert의 수 K를 고정하고 전체 expert의 수 n을 증가시키면, 전체 모델의 파라미터 수는 증가하지만 연산 비용은 효율적으로 유지할 수 있다. n의 증가에 따라서 모델의 전체 파라미터 수(sparse parameter count)가 변동되고, k의 증가에 따라서 각 토큰이 처리하는 파라미터의 수(active parameter count)는 변동된다.
expert의 수가 증가하여 전체 파라미터 수가 늘어나도, 토큰의 연산은 top-k개의 expert만 진행하기 때문에 모든 파라미터와 연산하지 않고 일부 파라미터만 사용한다.
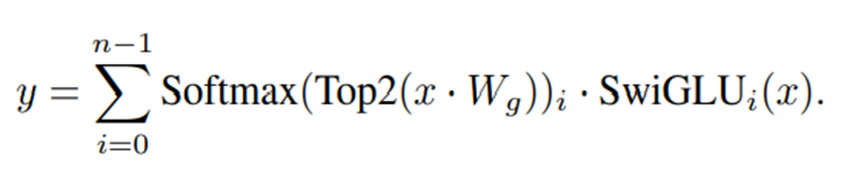
MoE layer는 각 토큰에 개별적으로 적용된다. 또한 MoE layer는 transformer block의 feed-forward(FFN) sub-block이 교체된다. Mixtral은 expert function에서 SwiGLU 아키텍처를 사용했고 K= 2로 지정했다. 각 토큰은 두 개의 SwiGLU 서브블록 가중치와 라우팅된다. 이 공식은 GShard의 아키텍처와 유사하다. 차이점으로 여기선 모든 FFN sub-block을 MoE layer로 교체했지만 GShard는 다른 부분도 교체했다.

간단한 코드 리뷰
이해를 위해서 논문에 적힌 github code를 살펴보았다.
GitHub - mistralai/mistral-src: Reference implementation of Mistral AI 7B v0.1 model.

Mixtral은 트랜스포머 아키텍처를 기반이다. layers는 TransformerBlock이 n_layers(=32) 번 반복되는 구조이다.

transformer block의 feed-forward(FFN) sub-block이 MoeLayer로 교체된다.
Mistral 7B에서 self.feed_forward = FeedForward로 정의했다. 여기 Mixtral 8x 7B은 MoeLayer로 교체했다. MoeLayer는 experts와 gate로 구성된다. experts는 Mistral 7B의 self.feed_forward와 동일한 구조의 FeedForward가 8개로 구성된다.

임베딩한 토큰들이 x로 forward에 입력되고 attention에서 연산 후 다시 x와 add된다. 이 값을 h로 정하고 normalization 후 MoeLayer의 input으로 입력한다.


MoeLayer의 gate는 TransformerBlock에서 정의했다. nn.Linear로 4096(=dim) size로 입력되면 8(=num_expert) size로 선형 변환한 8개의 logit 값을 출력한다.

expert는 mistral의 FeedForward와 동일한 구조이다. 동일한 구조의 FeedForward가 8개로 구성된다.
SwiGLU인 silu()함수를 이용한다.
FeedForward는 4096 size를 입력으로 받아 다시 4096 size로 반환한다.

- input의 shape은 (batch_size, sequence_length, dim=4096)이다.
- input_squashed에서 (batch_size * sequence_length, dim=4096)으로 squash한다.
- gate에 input_squashed을 입력한다.
gate_logits.shape == (batch_size * sequence_length, num_expert=8) - gate_logits에 topk 함수를 적용한다. 8개의 gate_logits 중 가장 큰 순서로 두 개의 logits을 선택하여 weights로 반환한다. 그리고 사용할 expert의 번호는 selected_experts에 저장한다.
weights.shape == selected_experts == (batch_size * sequence_length, topk=2) - topk로 선택된 두 개의 weights에 softmax를 취해 logit 2개에 대한 확률을 구한다.
weights.shape == (batch_size * sequence_length, topk=2)
예시 shape 변화
# batch_size = 2
# seq_len = 3, context_len = 32768을 편의상 축소
# dim = 4, dim = 4096을 편의상 축소
# token.shape = batch_size, seq_len = (2,3)
token =[[[나는],
[밥을],
[먹는다]],
[[너는],
[짜장면],
[먹었다]]]
#input
# Moelayer의 input (batch_size, seq_len, dim)
# input shape = (2,3,4)
tensor([[[ 1.2985, 0.7261, 0.4030, -0.7106],
[ 1.1694, 0.2378, 0.9664, -0.9000],
[-0.4219, -0.3330, -1.1978, -1.6016]],
[[-0.2406, 0.3493, -0.4387, 1.3484],
[ 0.9783, -0.4448, -2.0113, -1.1817],
[-0.4885, 0.3492, -0.0738, -0.8218]]])
#input_squashed
#(batch_size*seq_len, dim)으로 변환
#shape = (6,4)
tensor([[ 1.2985, 0.7261, 0.4030, -0.7106],
[ 1.1694, 0.2378, 0.9664, -0.9000],
[-0.4219, -0.3330, -1.1978, -1.6016],
[-0.2406, 0.3493, -0.4387, 1.3484],
[ 0.9783, -0.4448, -2.0113, -1.1817],
[-0.4885, 0.3492, -0.0738, -0.8218]])
# gate에 input_squashed 입력
# weights.shape = (6,8)
tensor([[-0.7046, 0.3174, -0.8371, -0.2128, -0.7265, 0.5239, 0.4140, -0.7686],
[-0.3765, 0.2417, -0.7899, -0.5537, -0.3276, 0.3217, 0.0499, -0.9069],
[ 0.0748, 0.1156, -0.1076, 0.5116, -0.6876, 0.8101, -0.0188, 0.3488],
[-1.0672, 0.5990, 0.5185, 0.3113, 0.5823, 0.2263, 0.4124, 0.7399],
[-0.8083, 1.1250, -0.0456, 0.5542, -1.3719, 1.4850, 0.5771, 0.7325],
[-0.0332, -0.2452, -0.2837, 0.2264, -0.1090, 0.2357, -0.0333, -0.1717]],
grad_fn=<AddmmBackward0>)
#weights, selected_expert = torch.topk(weights, 2)
#topk 적용한 가장 큰 두 개의 logit
#weights shape = (6,2)
tensor([[0.5239, 0.4140],
[0.3217, 0.2417],
[0.8101, 0.5116],
[0.7399, 0.5990],
[1.4850, 1.1250],
[0.2357, 0.2264]]
# 8개의 logit 중 몇 번 째인지 = 몇 번 expert를 사용할 것인가
#selected_expert shape = (6,2)
tensor([[5, 6],
[5, 1],
[5, 3],
[7, 1],
[5, 1],
[5, 3]])
# weights에 softmax 적용
# topk 2개의 logit에 대한 확률값
# shape = (6,2)
tensor([[0.5274, 0.4726],
[0.5200, 0.4800],
[0.5741, 0.4259],
[0.5352, 0.4648],
[0.5890, 0.4110],
[0.5023, 0.4977]], grad_fn=<SoftmaxBackward0>)
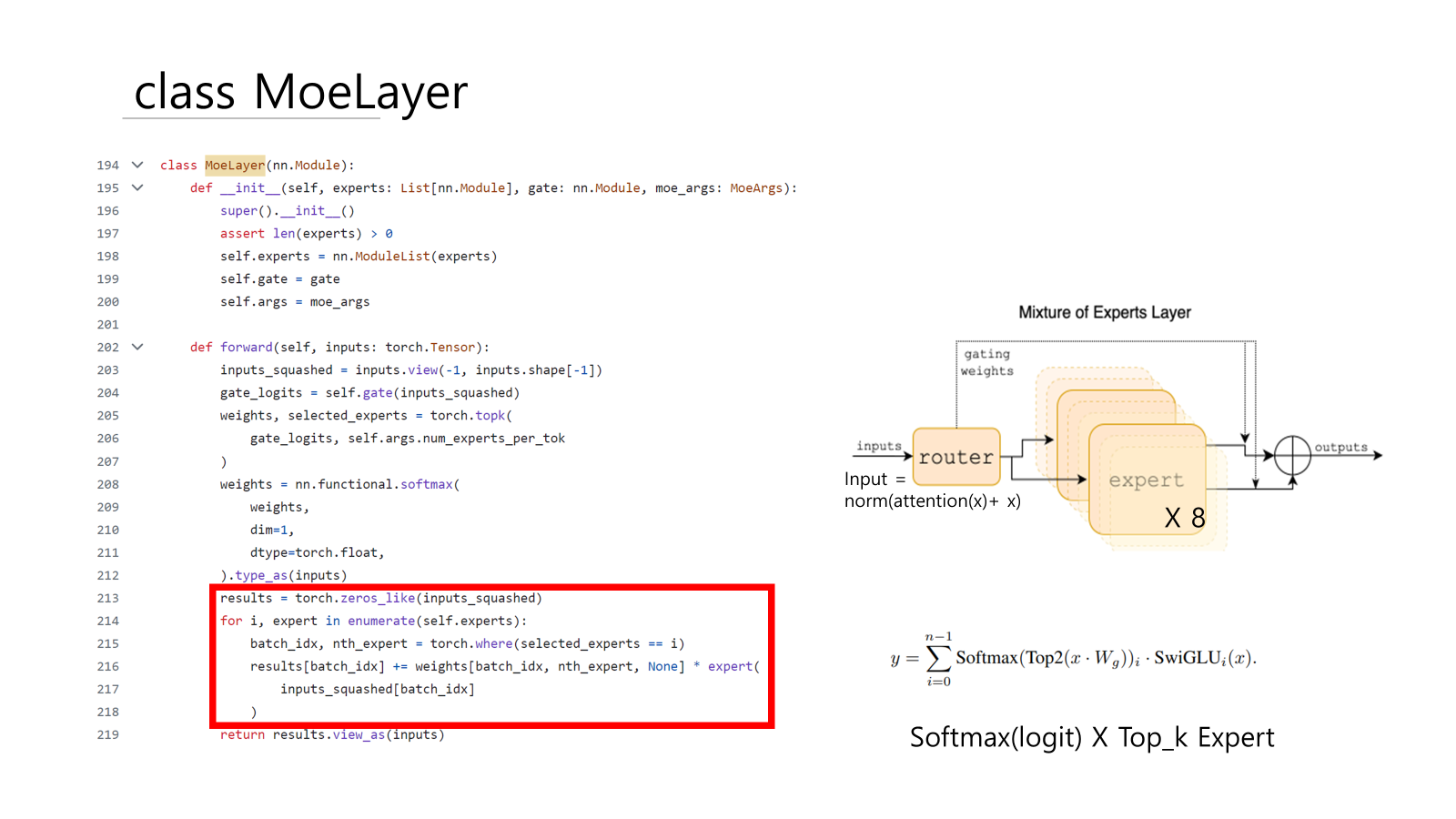
- result에 inputs_sqashed와 동일한 shape의 0행렬을 만든다.( batch_size*seq_len, dim)
- 8개의 FeedForward로 구성된 expert를 번호대로 순회한다.
- 각 토큰을 gate에서 선택한 두 개의 expert에 입력한다. 그리고 softmax를 적용한 weights를 각각 곱한다.
- 두 개의 expert는 sparse한 즉 분리된 가중치. 따라서 weights가 확률 0%와 100%를 반환하여도 expert와 weights의 가중합이 0이 되지 않는다.
- 0행렬인 results에 더해준다.
- result의 shape을 (batch_size*seq_len, dim)에서 input의 (batch_size, seq_len, dim)으로 다시 바꿔준다.

MoeLayer의 output을 h와 더한다.
out을 다음 layer의 input으로 입력 후 레이어의 개수만큼 반복한다.
중간 정리
- embedding layer와 attention layer의 파라미터 수와 구조는 크게 변동이 없다.
- FFN의 Gate와 expert*8가 추가되었고 파라미터가 증가한다.
- 따라서 sparse parameter count는 7Bx8 = 56B이 아니라 42B이 된다.
- 8개의 expert 중 2개만 선택하기 때문에 Active parameter count는13B이다.
3 Results
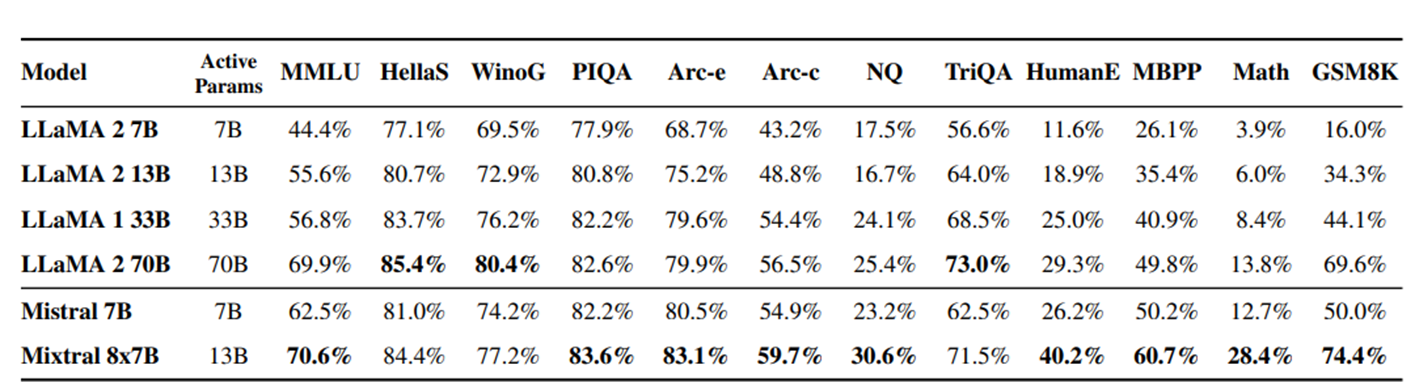
라마 모델들과 비교했다. LLaMa 2 70B과 비교했을 때 많은 벤치 마크에서 우수한 성능을 보였다. 특히 수학, 코드 생성에서 뛰어남을 확인했다.
Size and Efficiency

Mixtral은 active parameters 13B 파라미터만 사용하여 LLaMa 70B보다 뛰어났다. 5배 낮은 active parameters로 더 뛰어난 성능을 보인다.
Comparison with Llama 2 70B and GPT-3.5

Mixtral과 Llama 2 70B, GPT-3.5와 비교했을 때도 우수한 성능을 보였다.
3.1 Multilingual benchmarks

3.2 Long range performance

3.3 Bias Benchmark

4 Instruction Fine-tuning
Mixtral – Instruct은 supervised fine-tuning (SFT)와 Direct Preference Optimization (DPO)방식으로 instruction을 fine-tune했다. Chat 벤치마크에서 GPT-3.5-Turbo, Gemini Pro, Claude-2.1, Llama 2 70B chat보다 우수한 성능 확인했다.
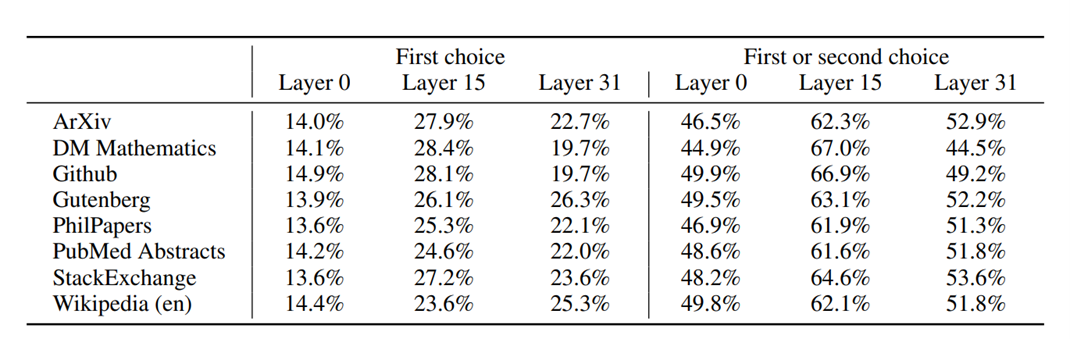
5 Routing analysis


6 Conclusion
'논문 리뷰' 카테고리의 다른 글
| Griffin: Mixing Gated Linear Recurrences withLocal Attention for Efficient Language Models (0) | 2024.07.19 |
|---|---|
| [BiGS]Pretraining Without Attention(SSM) (0) | 2024.06.10 |
| [Transformer] Attention Is All You Need (0) | 2024.04.25 |
| [GPT-2]language models are unsupervised multitask learners (0) | 2024.04.12 |
| [GPT-1]Improving Language Understanding by Generative Pre-Training (0) | 2024.03.07 |