
티스토리 뷰
Abstract
2022년 제출된 이 논문은 Bidirectional Gated SSM을 (BiGS) 제안한다. 당시 CNN, RNN 등으로 Attention을 대체하는 pretrain을 시도하지만 성능이 좋지 않았다. 논문은 BiGS가 처음으로 attention 없이 SSM layer로 BERT수준의 전이학습에 성공했다고 주장한다.
Background
State Space Models
state space model (SSM)은 continuous-time의 스칼라 input
x′(t)=Ax(t)+Bu(t)
y(t)=Cx(t)+Du(t)
방정식의 파라미터는

여기서 input 시퀀스를 discrete-time scalar
xk=ˉAxk−1+ˉBuk,
yk=ˉCxk+ˉDuk
ˉA ˉB uk xk ˉA ˉB ˉC xk yk ˉD uk
이 방정식은 RNN처럼 연산이 가능하다. 한편 RNN과 달리
BiGS Model
BiGS는 STACK Architecture, Gated Architecture 서로 다른 두 모델로 구성한다. 두 모델과 BERT의 성능을 비교하는 실험으로 평가한다. BERT는 Bidirectional adaptation으로 attention을 통해 context의 position에 관계없이 token의 정보를 얻을 수 있다. BiGS는 Two sequential SSM으로 Bidirectional 정보를 얻는다. SSM은 S4D로 구성하고, Multiplicative Gating 적용한 Gated Architecture로 BERT의 성능을 재현했다.
STACK Architecture
Stack SSM은 트랜스포머와 같은 구조이다. BERT Layer의 multi-head self attention을 Two sequential SSM으로 교체했다.
Two sequential SSM
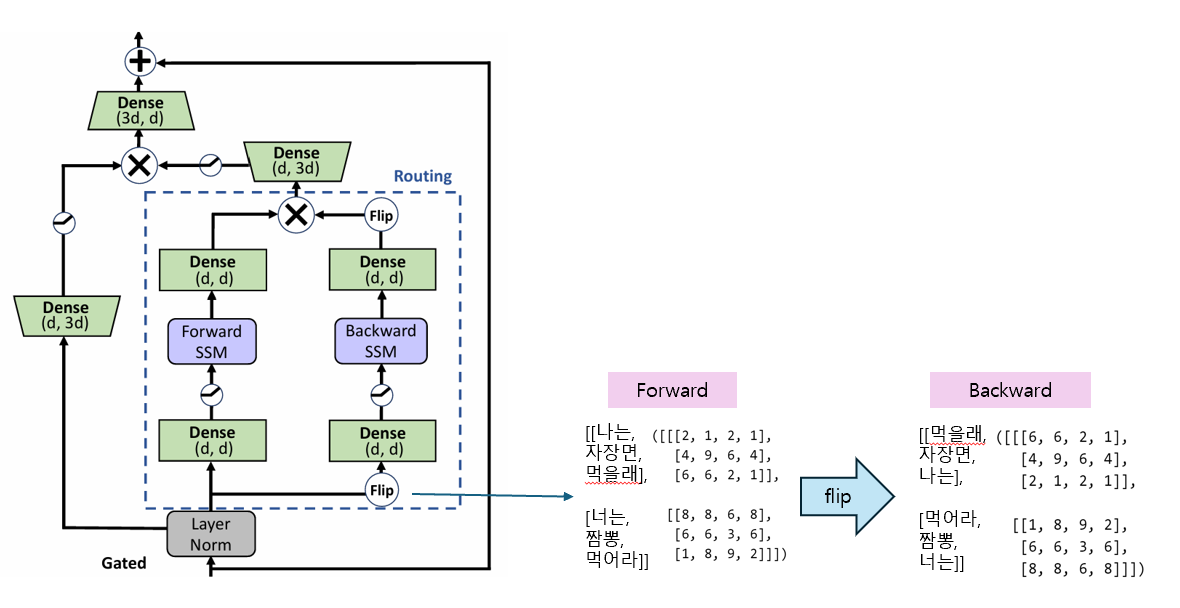
BERT는 어텐션을 이용해 양방향 정보를 모두 얻을 수 있다. 반면 SSM은 RNN처럼 한 번에 양방향의 정보를 얻을 수 없다. 따라서 Forward의 정보와 Backward의 정보를 Two sequential SSM로 학습한다. Two sequential SSM은 Forward SSM과 Backward SSM으로 구성된다. SSM은 S4로 동일하게 구현된다. 단순히 Flip에서 문장을 반전하여 SSM을 두 번 연산한다. 이후 다시 Flip 하여 element-wise multiplication으로 정보를 반영한다.
Gated Architecture
논문은 총 세 가지 스텝으로 구분한다. 먼저 임베딩을 세 개의 hidden state로 linear transformation 한다. forward의
두 번째 스테이지는 Two sequential SSM 연산 후 element-wise multiplication(⊗) 연산을 한다.
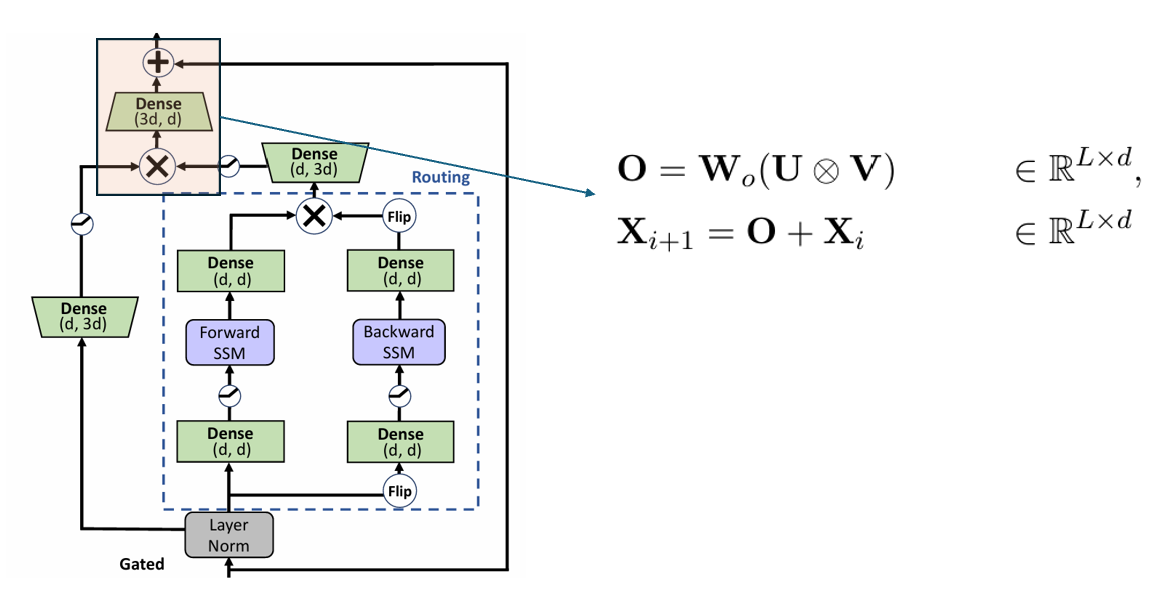
마지막으로 Two sequential SSM output
Experiment
실험은 SSM 모델들과 attention 모델들을 비교했다. 사전학습은 BERT와 동일하게 next-sentence prediction이 아닌 masking strategy를 사용했다. 사전학습에서 모델의 파라미터 수와 학습 토큰 수를 유사하게 통제했다. BERT-Large의 파라미터는 350M 수준이다. Gated SSM은 23 layer와 STACK models은 24 layer를 사용해 유사한 파라미터 수로 맞췄다. ablation tests를 위해서 세 가지 규모로 사전학습 규모를 정했다(11B (short), 29B (medium), and 97B (full)). SSM 모델은 context length를 128로 사전훈련을 마쳤다. 이후 더 긴 시퀀스에 적응시키기 위해서 512, 4096 토큰으로 추가 학습했다. pretrain 이후 benchmarks에 fine-tuning 후 평가했다.
Result & Analysis
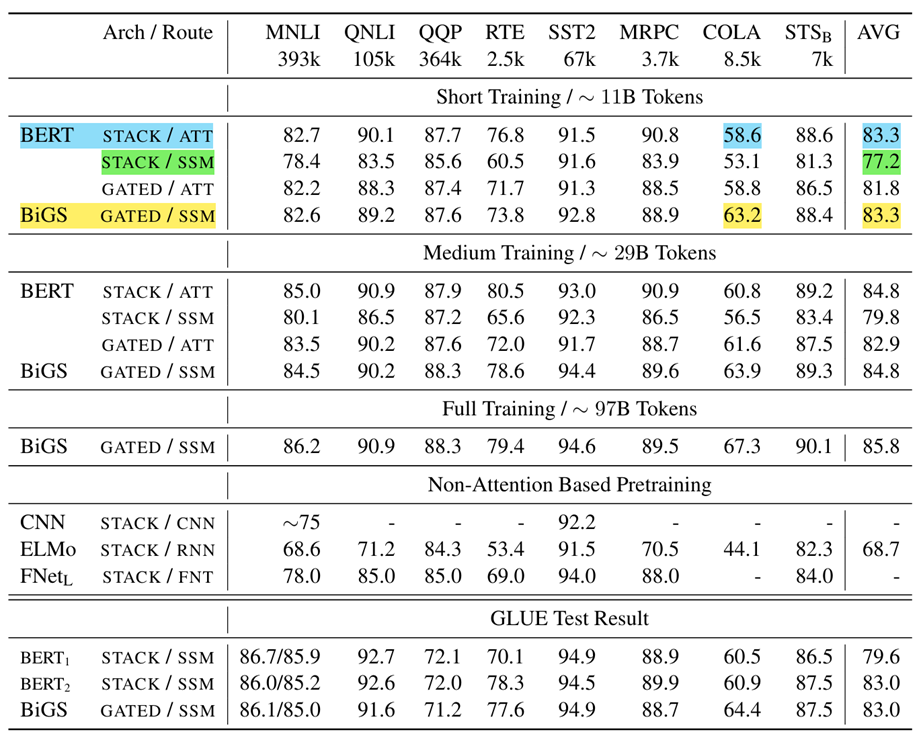
BERT, Stack SSM, Gated SSM을 비교했다. Stack은 BERT보다 성능이 낮았고, Gate를 적용한 Gated SSM으로 BERT의 성적을 재현했다. Multiplicative Gating이 SSM보다 성능에 큰 영향을 주었는지 attention에도 적용했다. attention에 gate를 적용했을 때는 오히려 성능이 떨어졌음을 확인했다. BERT와 평균 점수는 비슷하지만 COLA task를 제외하면 전반적으로 낮은 성능을 보인다. COLA task에 유독 좋은 성능을 보였고, 논문은 추가 조사가 필요하지만 SSM-routing이 transformer와 다른 inductive bias가 있는 것 같다고 언급했다.
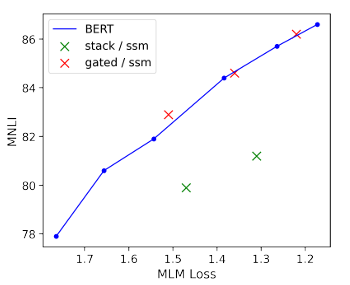
Gated ssm은 pretrain Loss와 down-stream accuracy가 BERT와 유사하지만 stack은 그렇지 않음을 확인했다.
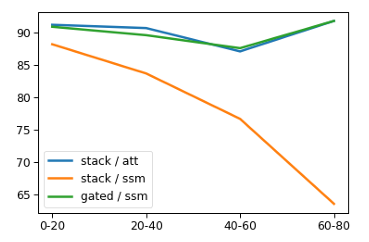
또한 multiplicative gating이 long-distance interactions의 일반화 성능에 도움을 주는 점을 관찰했다.
Conclusion
BiGS로 attention 없이 pretrain에 성공했다. BiGS는 SSM-based routing과 multiplicative gating으로 구성된다. SSM만으로 이루어진 Stack 아키텍처는 성능이 좋지 않지만, Gating으로 성능을 일반화하는데 도움이 된다. BiGS는 attention 없이 BERT를 재현한 사례임을 말한다.
'논문 리뷰' 카테고리의 다른 글
| Griffin: Mixing Gated Linear Recurrences withLocal Attention for Efficient Language Models (0) | 2024.07.19 |
|---|---|
| [Transformer] Attention Is All You Need (0) | 2024.04.25 |
| [GPT-2]language models are unsupervised multitask learners (0) | 2024.04.12 |
| [GPT-1]Improving Language Understanding by Generative Pre-Training (0) | 2024.03.07 |
| [Mixtral 8x7B] Mixtral of Experts 리뷰 (0) | 2024.01.29 |