
티스토리 뷰
Griffin: Mixing Gated Linear Recurrences withLocal Attention for Efficient Language Models
HJunS 2024. 7. 19. 15:38

Abstract
RNN은 빠른 inference와 long sequences에서 효율적으로 확장할 수 있다. 하지만 훈련과 확장이 어렵다. 논문은 gated linear recurrences의 Hawk와 gated linear recurrences와 local attention을 적용한 Griffin을 소개한다. Hawk는 다운스트림 task에서 Mamba의 성능을 능가하고, Griffin은 LLama-2의 6배 이상 적은 토큰으로 훈련되었음에도 성능이 일치한다. 모델은 Train 중에 Transformers의 하드웨어 효율성과 일치하고, 동시에 Inference에서 낮은 latency와 throughput이 높다. Griffin을 14B까지 확장하고 효율적인 분산 훈련을 위해 shard하는 방법을 소개한다.
Introduction
RNN은 NLP 리서치와 딥러닝의 초기에 중심적인 역할을 했다. 이후 multi-layer perceptrons(MLPs) 와 multi-head attention (MHA)를 interleaves한 Transformers가 등장했고 뛰어난 성능을 보였다. 하지만 트랜스포머는 global attention의 quadratic complextity 문제 때문에 긴 시퀀스로 확장이 어렵다. 또한 시퀀스의 길이에 따라 Key-Value(KV) cache가 선형적으로 증가하기 때문에 추론에서 속도가 느려진다. Multi-Query Attention (MQA)로 캐시 크기를 일정한 비율로 줄여 완화하나 여전히 시퀀스의 길이에 선형으로 증가한다. Recurrent language model은 전체 시퀀스를 반복적으로 업데이트되는 a fixed-sized hidden state로 압축하기 때문에 대안이 된다. 하지만 트랜스포머를 대체할 RNN은 규모에 따른 성능과 유사한 하드웨어 성능을 달성해야 한다.
논문은 MQA를 대체하기 위해서 Recurrent block의 gated linear recurrent layer인 Real-Gated Linear Recurrent Unit (RG-LRU layer)를 새롭게 제안한다. 논문은 이 recurrent block으로 Hawk와 Griffin을 만들었다. Hawk는 recurrent blocks과 MLPs를 결합했다. Griffiin은 hybrid model로 MLPs와 recurrent blocks과 local attention을 혼합하여 만들었다.
- Griffin과 Hawk는 이전에 7B이상에서 트랜스포머에서 관찰한 held-out loss와 FLOPs 사이에서 멱법칙(power law) 거듭 제곱의 scaling을 보여준다.

- Griffin은 Transfomer보다 낮은 held-out loss를 달성한다.
- Griffin과 Hawk를 300B 토큰으로 overtrain했다. Hawk3B은 Mamba-3B의 절반의 토큰으로 훈련되었어도 다운스트림에서 능가한 성능을 보였다. Griffin-7B 및 Griffin-14B는 약 7배 적은 토큰으로 훈련되었음에도 불구하고 Llama-2의 성능과 일치했다.
- Griffin과 Hawk 모두 트랜스포머와 비슷한 training efficiency를 달성한다. diagonal RNN layers의 memory bound 문제를 RG-LRU layer로 구현하기 위해서 Pallas로 구현했다. memory transfer를 최소화한다.
- Griffin과 Hawk 모두 MQA 트랜스포머보다 높은 처리율(throughput)을 달성한다. 그리고 긴 시퀀스를 샘플링할 때 더 낮은 레이턴시를 달성한다.
- Griffin은 훈련보다 긴 시퀀스로 평가했을 때 트랜스포머보다 성능이 좋다. 또한 copying과 retrieval 데이터도 효율적으로 학습한다.그러나 Hawk와 Griffin은 파인튜닝 없이 사전학습 모델로만 평가할 때 트랜스포머보다 성능이 낮다.
Model Architecture
모델은 세 블럭으로 구성한다.
- residual block
- MLP block
- temporal-mixing block
i) residual block과 (ii) MLP block은 모든 모델에 동일하게 적용한다. (iii) temporal-mixing block은 global Multi-Query Attention (MQA), local (sliding-window) MQA , 논문에서 제안하는 Real-Gated Linear Recurrent Unit (RG-LRU)가 적용된 recurrent block 세 가지 중에 고려한다.
residual block은 pre-norm Transformers의 구조에서 영감을 받았다. 입력 시퀀스를 임베딩 후 N개의 블럭을 지나, RMSNorm을 적용하고 마지막에 activation을 적용한다. 토큰의 확률을 계산하기 위해 마지막 레이어에 softmax를 적용한다. 이 마지막 레이어는 input embedding layer와 가중치를 공유한다.
Residual block
Residual block에는 두 가지 구성 요소가 있다. 첫 번째는 hidden state
MLP block
Temporal-mixing blocks
Temporal-mixing blocks은 시퀀스의 다른 시간적 위치(temporal location)를 집계해 은닉층을 활성화한다. global MQA, local MQA, Recurrent block 중에서 선택한다.
Global multi-query attention
Multi-head attention을 사용하지 않고 base transformer에 Multi-query attention 사용했다.
Local sliding window attention
Global attention의 문제점은 complexity가 quadratical 증가한다. 해결책으로 sliding window attention으로 불리는 local attnetion을 채택했다. KV크기를 제한하여 quadratic하지 않다.
Recurrent block
separable Conv1D layer를 사용하는 Shift-SSM in H3의 영감을 받았다. temporal filter dimension은 4이다. RG-LRU 레이어를 거쳐 GeLU를 적용하고 merge한다.
Real-Gated Linear Recurrent Unit (RG-LRU)
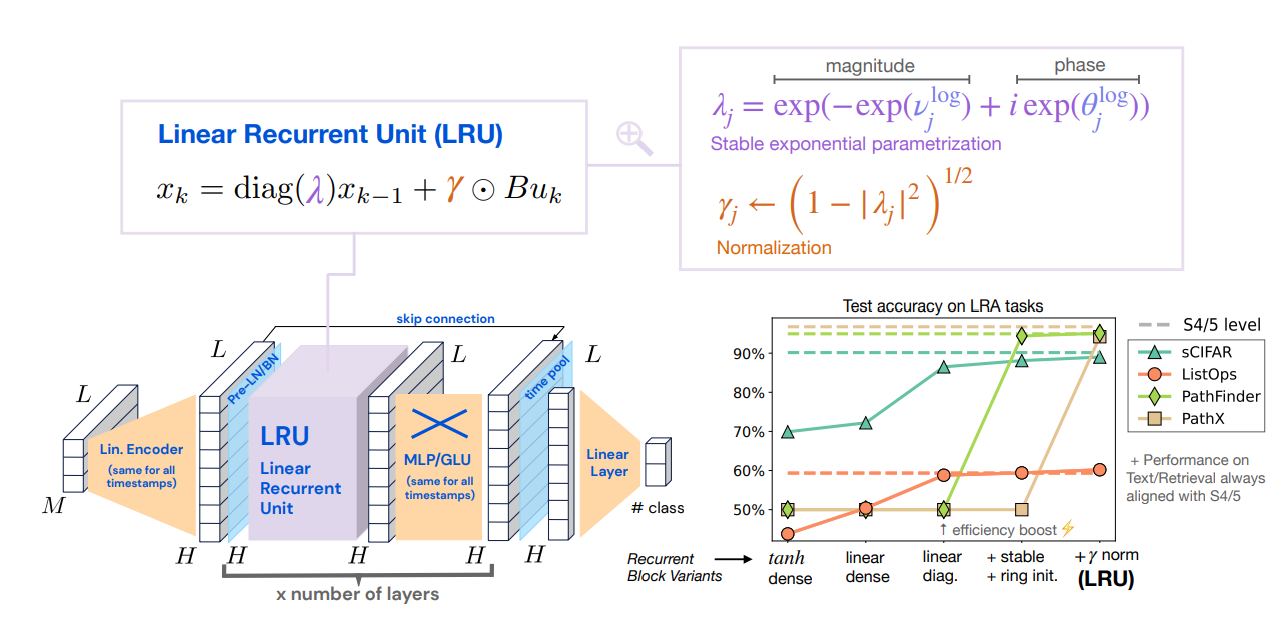
Linear Recurrent Unit (LRU)에서 영감을 받아 RG-LRU를 제안했다.
(1)recurrence gate rt=σ(Waxt+ba),
(2)input gate it=σ(Wxxt+bx),
(3)a=σ(Λ)
at=acrt,
(4)ht=at⊙ht−1+√1−a2t⊙(it⊙xt),
- output은
yt=ht σ a Λ a - variable
c - 안정성을 위해서
acr logat=logacrt=logσ(Λ)crt=−csoftplus(Λ)⊙rt - SSM과 다르게 orthogonal polynomials 이론으로 initialization하지 않는다.
- discretization을 정의하지 않는다.
- complex recurrences를 사용하지 않는다.
Result
| Base-Transformer | Hawk | Griffin | |
| MLP block | Gated MLP block | Gated MLP block | Gated MLP block |
| Attention | Global multi-query attention | X | Local sliding window attention |
| Recurrent block | X | RG-LRU | RG-LRU |
세 모델을 비교하는 실험을 진행한다.
Evaluation on downstream tasks
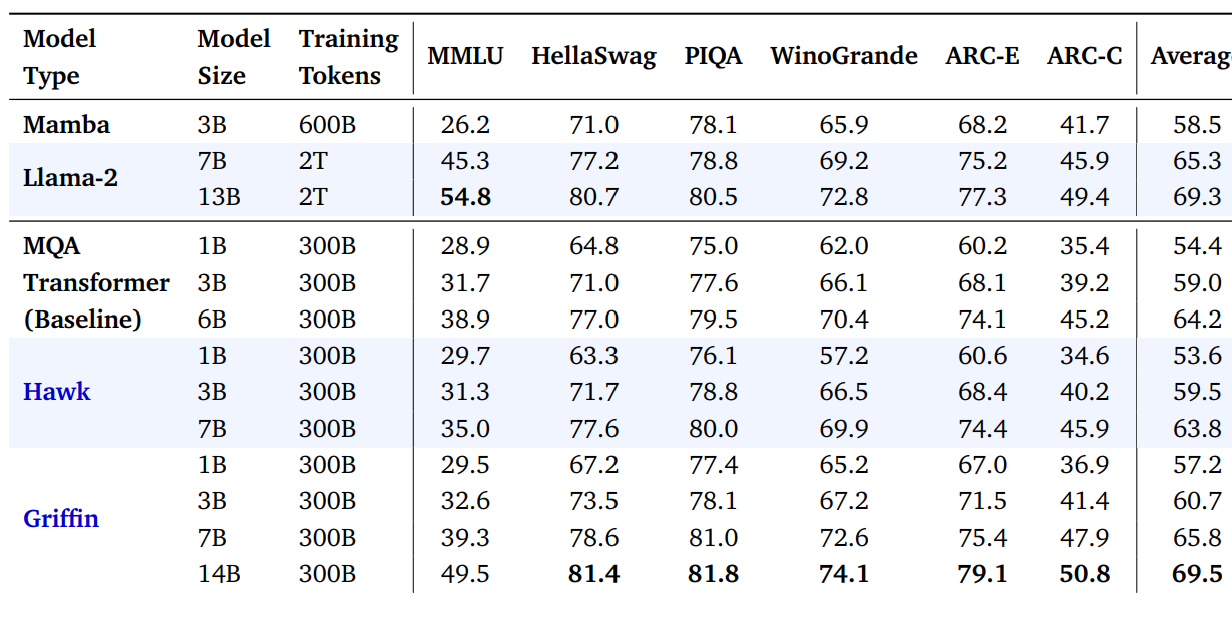
Hawk와 Grifin이 더 적은 토큰으로 더 높은 성능을 보인다.
Latency & Throughput
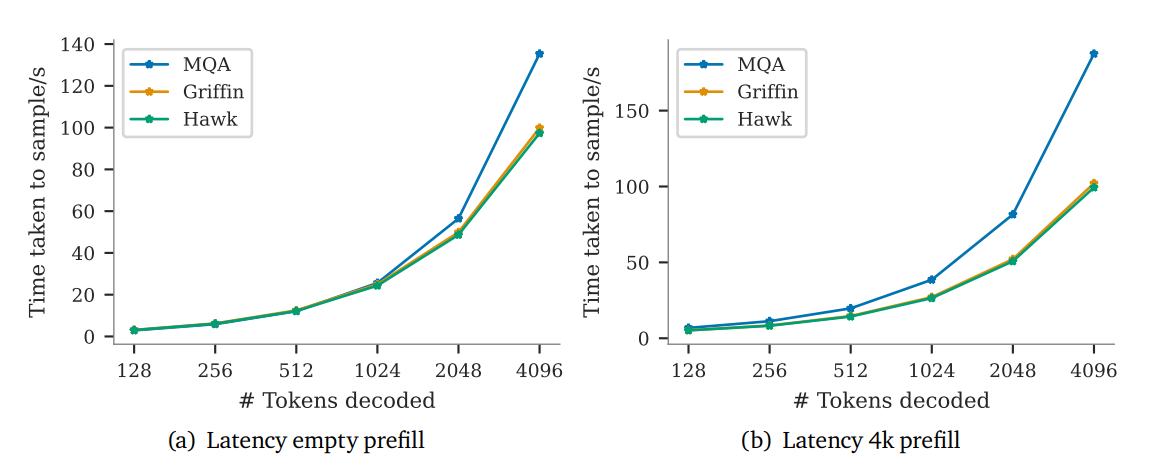
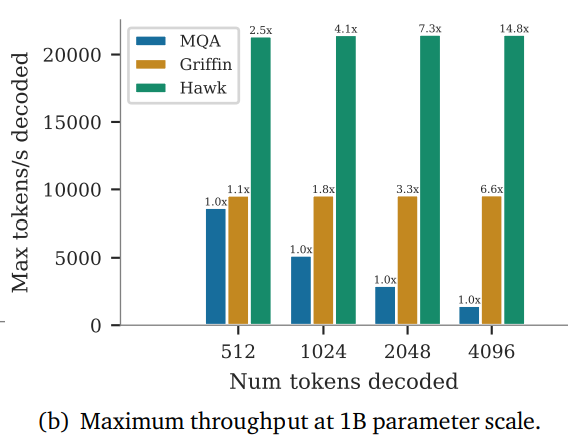
Hawk와 Griffin 모두 MQA Transformer보다 낮은 latency와 높은 throughput의 성능을 보인다.
Conclusion
RG-LRU를 이용한 Hawk를 소개한다. 또한 RG-LRU layer와 local attention mix한 hybrid 모델 Griffin을 소개한다.
Hawk는 절반의 토큰만 학습해 Mamba의 다운스트림 성능을 초과하고, Griffin은 6배 이상 적은 토큰으로 훈련했을 때 Llama-2의 성능을 약간 능가한다. Hawk와 Griffin은 base Transformer와 inference-time을 validate 비교했을 때 latency가 감소하고 througput이 크게 증가함을 관찰했다. Hawk와 Griffin은 더 킨 시퀀스를 외삽(extrapolate)할 수 있다. 이 결과는 Global attention의 대안을 제공한다.
'논문 리뷰' 카테고리의 다른 글
| [BiGS]Pretraining Without Attention(SSM) (0) | 2024.06.10 |
|---|---|
| [Transformer] Attention Is All You Need (0) | 2024.04.25 |
| [GPT-2]language models are unsupervised multitask learners (0) | 2024.04.12 |
| [GPT-1]Improving Language Understanding by Generative Pre-Training (0) | 2024.03.07 |
| [Mixtral 8x7B] Mixtral of Experts 리뷰 (0) | 2024.01.29 |