
티스토리 뷰
ABSTRACT
문제 정의
- 이 논문은 GUI agents 개발이 오픈소스와 차이가 너무 크기 때문에, GPT-4o, GeminiPro-Vision과 같은 상용 비전-언어 모델VLM에 크게 의존하는 한계를 이야기한다.
- 특히 GUI grounding 과 Out-Of-Distribution OOD scenarios에서 오픈소스 모델의 성능이 크게 차이 난다
문제 해결
OS-Atlas
- foundational GUI action model인 OS-Atlas를 개발했다.
- 데이터와 모델링 측면을 개선해 GUI grounding 과 OOD agentic tasks에도 탁월한 성능을 보인다.
GUI Data 데이터 합성(Synthesizing GUI grounding data)
- Windows, Linux, macOS, Android, 웹 등 다양한 플랫폼에서 GUI grounding 데이터를 자동 생성할 수 있는 Tool을 개발했다.
- 오픈소스 툴킷을 제작해 GUI elements를 포함하는 13 million이 이상의 오픈소스 데이터셋을 공개했다.
결과
- 이 데이터로 OS-Atlas는 GUI의 스크린샷을 이해하고 보지 못한 인터페이스에서도 일반화할 수 있다.
- 6개의 벤치마크에서 SOTA를 달성했다.
1 INTRODUCTION
LLM을 적용해 다양한 task를 진화시키고 있고, 아이언맨의 자비스가 현실이 되고 있다.(실제로 쓰인 말)
최근 연구 방향
- 많은 에이전트가 HTML이나 accessibility trees처럼 텍스트 기반 정보를 바탕으로 의사결정을 한다.
- 그러나 이 정보들은 길이가 길고, 노이즈가 많고, 수집이 어렵다는 한계가 있다.
GUI agent
- 이 문제를 극복하기 위해서, 유저의 화면을 보고 분석하는 large vision language models (VLMs) 기반 GUI agent가 개발되고 있다.
Action model
- GUI agent의 핵심이다.
- 자연어 명령을 운영체제가 실행 가능한 액션으로 변환하는 모델이다.
- GUI grounding 능력이다.
GUI grounding
- GUI 환경에서 자연어 명령을 실행 가능한 형태로 연결
- 예시) 화면 클릭, 스크롤바 내리기, 타이핑하기
기존 GUI action model의 한계
- 오픈소스 기반 VLM은 GUI grounding 성능이 낮고, OOD 일반화가 잘 되지 않는다
- 첫째, 기존 VLM은 GUI 스크린샷에 대해 거의 사전학습되지 않았다.
- 웹사이트나 모바일 앱의 스크린샷의 시도만 있었다.
- Windows, MacOS, Linux, iOS, Android 등 다양한 플랫폼과 해상도, 애플리케이션을 포괄하는 대규모 공개 GUI 스크린샷 코퍼스가 부족하다.
- GUI는 유사한 설계 원칙으로 작동하기에, 이러한 데이터를 기반으로 사전학습을 한다면, GUI grounding과 OOD 일반화 성능이 향상될 것이다.
- 둘째, 현재 데이터셋의 내용과 형식이 플랫폼마다 매우 다르다.
- 동일한 액션이 플랫폼마다 다르게 라벨링되는 문제가 있다.
- 예시) 데스크탑에서는 ‘click’, 모바일에서는 ‘tap’
- 용어의 불일치는 모델의 학습에 혼동을 주어 성능 저하를 유발한다.
GUI agent 개선안 제시
- Windows, macOS, Linux, Android, 웹을 포함한 멀티 플랫폼 GUI grounding 데이터 생성 툴킷 개발
- 데이터 툴킷으로 대규모 GUI grounding 데이터셋 구축했다. 2.3 million 스크린샷, 13 million GUI elements 이상의 양이다.
- 데이터 개선으로 훈련 과정에서 액션의 이름이 주는 혼동을 해결한다. 다양한 플랫폼에서 높은 정확도를 예측할 수 있는 OS-Atals는 세 가지 모드를 지원한다.
- 모바일, 데스크탑, 웹을 포함한 6개 벤치마크에 대한 성능 평가한다.
2 RELATED WORK
GUI Executable Language Grounding
- GUI Executable Language Grounding 또는 GUI grounding이라 한다.
- LAM(Large Action Model)의 핵심 기능은 자연어(Natural Language, NL) 명령(instructions)을 action과 관련된 파라미터(예: UI element의 좌표)로 변환하는 것이다.
GUI grounding training data
- 지시 표현 그라운딩 (REG, Referring Expression Grounding)
- 연어 명령 내에 명시적으로 언급된 UI 요소(예: "Open 버튼을 클릭해")를 기반으로 화면 상의 특정 요소를 찾아내는 것
- 웹은 크롤링 및 파싱을 통해 자동화할 수 있다.
- 데스크톱이나 모바일 플랫폼에서는 이 과정이 어렵다.
- 명령 그라운딩 (IG, Instruction Grounding)
- IG는 REG를 포함하는 상위 개념
- “Type”과 같이 특정 좌표를 요구하지 않는 행동도 포함한다.
- 명시적으로 어떤 요소를 가리키지 않는 경우도 있다.
- 예시) 마지막 파일 삭제
- 사람이 직접 주석을 달아야 하기 때문에 데이터 규모가 작고 다양성이 부족하다.
OS-Atlas의 해결책
데이터 수집의 어려움을 해결하기 위해서 다양한 플랫폼에서 데이터를 수집할 수 있는 인프라를 개발했다.
3 OS-ATLAS
데이터 측면과 방법론적 측면 모두 개선을 제안한다. OS-Atlas는 GUI agents로 설계된 첫 foundation action model이다.
3.1 TASK FORMULATION AND TRAINING
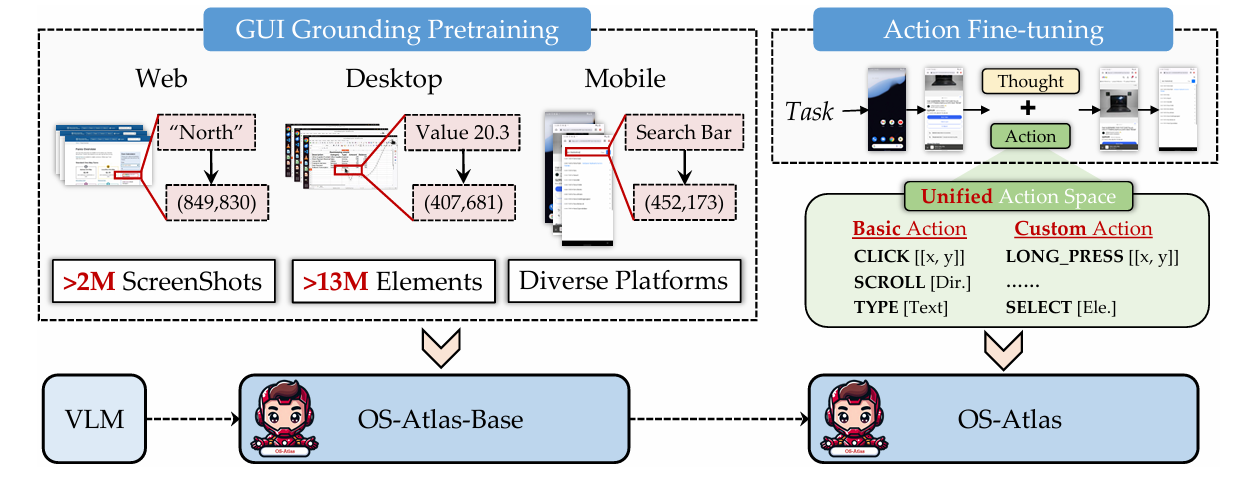
GUI Grounding Pre-training
- 이 모델은 OS-Atlas-Base이다.
- 입력: 스크린샷, element 지시사항
- 출력: element 좌표
- 대규모, 고품질, 다양한 형태의 데이터셋이 필요하다.
- 5개 주요 플랫폼을 포함하고, 2.3 million 이상의 스크린샷, 13 million 이상의 element를 포함한다.
Action Fine-tuning
- 입력: 스크린샷, task 지시사항, action history(이전까지 실행 action 정보)
- 출력: action
- action: thoughts, action type( CLICK, SCROLL ), action parameters(좌표).
- imitation learning을 진행한다. (사람이나 에이전트의 행동을 따라 하는 방식)
- 다양한 데이터셋을 같이 파인튜닝하면 action들의 confict가 성능 저하를 유발함을 확인했다.
- 이를 해결하기 위해 학습 과정에서 unified action space를 제안한다
3.2 GROUNDING DATA COLLECTION

- 기존 GUI grounding 데이터는 대부분 web에서 수집한 데이터이고, 양이 부족하다.
- OS-Atlas는 다양한 플랫폼에서 데이터를 제작했다.
Web
- 4 million 웹페이지를 크롤링했다.
- HTML의 element와 HTML attributes에서 파생된 참조 표현(referring expressions)과 좌표를 추출했다.
- 예시) 버튼, 스크롤바, 하이퍼링크, SVG image, title

- 이전 연구는 위의 정보만 추출했지만, 논문은 웹페이지를 렌더링 후 1920x1080 해상도의 스크린샷까지 수집했다.
- 오류 페이지(404 error)를 제외한 뒤, 3.7 million 웹페이지 스크린샷과 37 million elements를 선별했다.
- 사람이 판별한 결과 품질이 낮은 데이터가 다수 포함되었다.
- 규칙 기반(rule-base) 필터를 적용해 선별했다.
- 다양한 웹페이지 수집을 위해 한 페이지 당 최대 element를 10개로 제한했다.
- elements의 분포가 비정상적일 때 제거한다.(예: 화면 하단에 요소가 몰림)
- 최종적으로 1.6만 개 스크린샷과 7.7만 개의 element를 확보했다.
Desktop & Mobile
- 기존 방식은 수작업으로 데이터를 수집했기 때문에 규모가 작았다.
- 대규모 데이터를 생성하기 위한 두 가지 도전이 있다.
- 실제 운영체제 내에서 데이터를 수집하기 위한 시뮬레이션 환경을 설정
- 운영체제와의 인간 상호작용을 모방하여 시스템 상태를 변화시키고 새로운 스크린샷을 얻을 수 있도록 설계된 프로그램
데이터 수집 방법
- Android AndroidEnv
- Linux OSWorld
- Windows와 macOS 는 가상화의 어려움으로 실제 물리적 머신에서 데이터 합성 플랫폼을 배포하여 데이터를 수집
- A11y tree(Accessibility Tree)를 활용하여 그라운딩 데이터를 수집한다.
- Ubuntu에서는 pyatspi, Windows에서는 pywinauto, macOS에서는 ApplicationServices를 이용하여 A11y 트리에 접근한다.
- 시뮬레이션 환경에서 깊이 우선 탐색(DFS) 과 랜덤 워크(Random Walk) 방식으로 탐색한다.
Instruction Grounding Data Collection
- 기존 trajectory datasets을 활용해 GPT-4o로 Instruction Grounding data로 주석을 달았다.(annotation)
- GPT-4o
- 입력: 높은 수준의 작업 지시문(task instruction), action 전 스크린샷과 이후의 스크린샷
- 출력: 인터페이스의 변화를 분석해 action의 하위 명령(sub-instruction) 도출
- Set-of-Mark prompting 기법 사용하여 elements 위치를 명시
# 예시
Instruction: Enable dark mode
Before Screenshot: [이미지]
After Screenshot: [이미지]
Set-of-Marks:
- Element 1: button, label="Dark Mode", position=(134, 220)
# Sub-instruction: "Click the 'Dark Mode' toggle button in the settings menu."
3.3 UNIFIED ACTION SPACE
- 서로 다른 출처의 데이터를 혼합하여 멀티태스킹 파인튜닝을 하면, action space의 충돌(conflict)로 성능이 저하될 수 있음을 발견했다.
- 데스크톱 환경에서의 "click" 동작은 모바일 기기에서의 "tap" 동작과 논리적으로 동일하지만, 이러한 차이를 구분하지 않고 학습시키면 모델이 혼란을 겪을 수 있다.
- 논문은 기존 데이터셋의 형식을 표준화한 통합 액션 공간(unified action space)을 제안한다.
- 통합 방식은 프롬프트를 활용한다.
기본 액션 (Basic Actions)
- 기본 액션은 모든 플랫폼에서 공통적으로 사용 가능한 표준화된 동작이다.
- 현재 설계에서는 세 가지 기본 액션을 사용한다
- click (클릭)
- type (입력)
- scroll (스크롤)
사용자 액션 (Custom Actions)
- 사용자의 플랫폼 및 기기에 고유한 동작
- 모델은 사용자가 정의한 새로운 또는 이전에 본 적 없는 동작들까지도 지원할 수 있다.
- OS-Atlas가 범용 환경(out-of-distribution)에서도 높은 성능을 발휘하는 데 매우 중요하다
- open app: 지정된 애플리케이션을 여는 동작
- drag: 객체를 다른 위치로 이동시키는 동작

4 EXPERIMENTS: GROUNDING TASKS
4.1 EVALUATION DETAILS
벤치마크 (Benchmarks)
- ScreenSpot(Cheng 외, 2024)을 사용
- 단일 단계(single-step)의 GUI 그라운딩 능력을 측정하는 벤치마크다
- SreenSpot 데이터셋에서 약 11.32%의 주석 오류(annotation errors)를 발견했다.
- 수정된 그라운딩 데이터셋을 ScreenSpot-V2

https://huggingface.co/datasets/rootsautomation/ScreenSpot
설정 (Settings)
- 그라운딩 모드 설정 (Grounding Mode Setting)
- 플래너 모델(e.g., GPT-4o)을 그라운딩 전에 사용
- ScreenSpot의 명령어를 서브태스크(subtask) 명령어로 처리하고, 이를 플래너에 입력하여 보다 상세한 명령어를 생성
- 상세한 명령어를 그라운딩 모델에 입력
- VLM 입력을 위한 일종의 reasoning, CoT 작업이다.
- 표준 설정 (Standard Setting)
- 플래너 없이 ScreenSpot의 원래 명령어를 직접 사용하여 평가
모델 (Models)
- 백본에 따라 각각 OS-Atlas-Base-4B / 7B
- 두 모델은 image resolutions(이미지 해상도 처리) 방식이 다르다.
- InternVL-2 (Chen 외, 2024d): GUI 데이터 없이 학습된 모델
- InternVL-2-4B는 AnyRes(Liu 외, You 외, 2024)를 활용하여,
- 이미지를 리사이징한다.
- 큰 이미지를 더 작은 패치들로 분할한다.
- 각각을 독립적으로 비전 인코더로 인코딩한다.
- Qwen2-VL : GUI 데이터로 명시적으로 학습된 모델
- Qwen2-VL-7B는 arbitrary resolution 지원한다.
- 이미지를 동적으로 **시각 토큰(visual tokens)**의 수로 변환하여 처리한다.
평가지표 (Metrics)
- ScreenSpot의 그라운딩 정확도(grounding accuracy)
- 예측된 위치가 정답 UI 요소의 바운딩 박스 안에 포함될 경우 정답으로 간주된다.
- 미세한 오차(fine-grained errors)는 감지할 수 없다.
- IoU(Intersection over Union)
- IoU는 예측된 바운딩 박스와 정답 박스 사이의 겹침 정도를 수치화하는 지표다.

https://pyimagesearch.com/2016/11/07/intersection-over-union-iou-for-object-detection/
4.2 Results and Analysis
- Grounding Mode Setting과 Standard Setting 모두 OS-Atlas-Base는 모바일, 데스크탑, 웹 플랫폼에서 Sota를 달성했다.
- GUI 스크린샷을 기반으로 사전 학습(pre-training)된 Qwen2-VL도 GUI 그라운딩 전용 사전 학습을 추가하면 그라운딩 성능이 더욱 향상된다
The Effect of Grounding Data Scaling
- 데이터의 규모가 증가함에 따라 그라운딩 정확도와 IoU는 명확한 양의 상관 관계(correlation)를 보인다.
- 그라운딩 데이터를 계속해서 추가하면 성능 개선 가능성이 있다.
- 정확도(accuracy)는 상대적으로 상관성이 낮다. fine-grained errors는 알 수 없기 때문이다.
- 더 어려운 벤치마크와 정밀한 평가 지표가 필요하다

4.3 Application: Grounding Mode

| Grounding Mode | Action Mode | Agent Mode | |
| task | elements 좌표만 예측 | action 직접 생성(zero-shot) | 특정 목적에 파인튜닝 |
| 입력 | 스크린샷 + instruction( 작업 지시문) (Planner인 GPT-4o 출력) |
스크린샷 + instruction( 작업 지시문) |
스크린샷 + 작업 지시문 + 액션 히스토리(선택) |
| 출력 | elements coordinates (요소 좌표) |
액션 + argument(인자) (예시:클릭을 위한 좌표) |
액션 + argument(인자) (예시:클릭을 위한 좌표) |
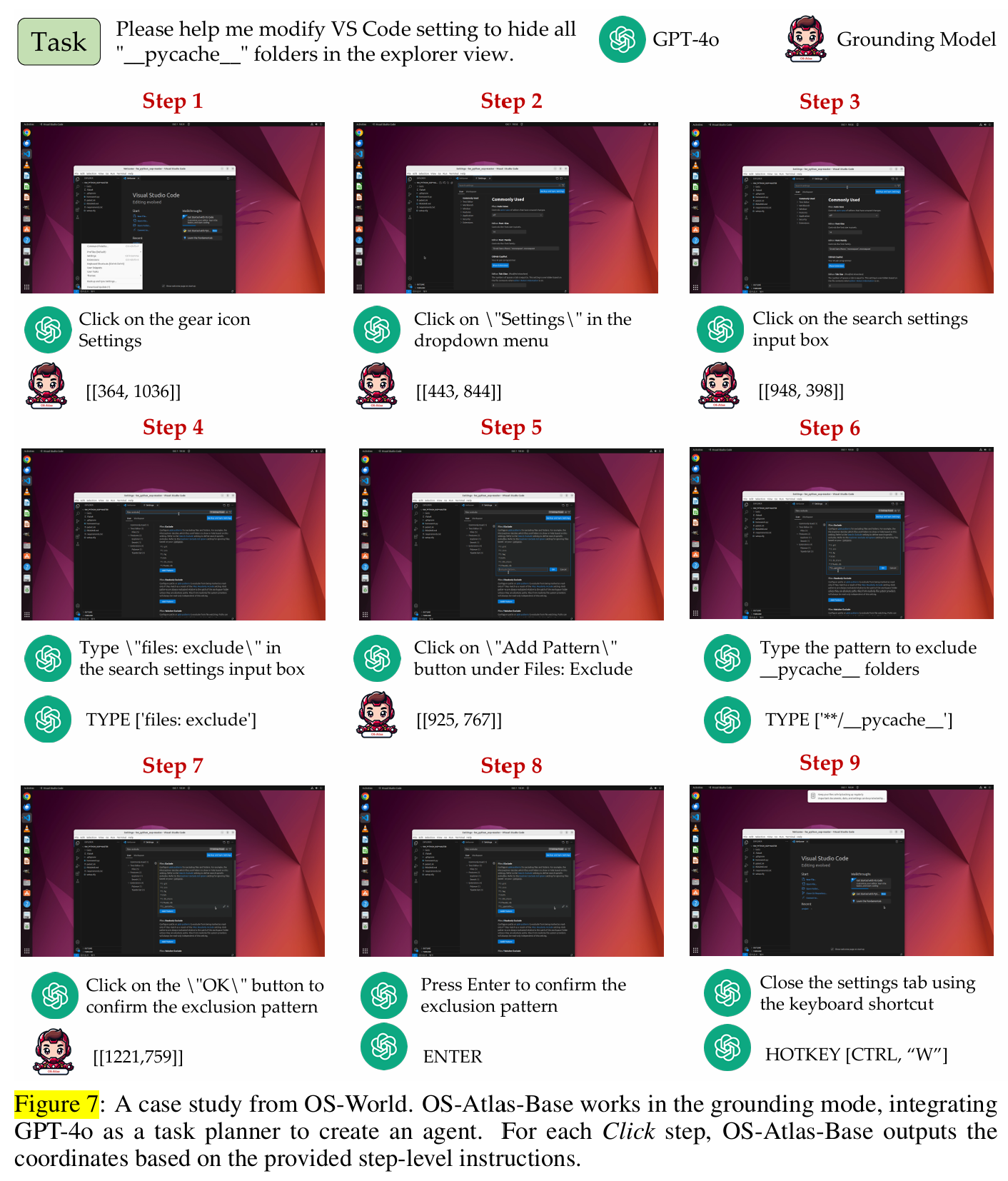
- Grounding Mode에서 OS-Atlas-Base가 어떻게 작동하는 평가했다.
- OS-Atlas-Base는 기존 GUI 에이전트의 그라운딩 모듈을 대체할 수 있고, 전체 성능을 향상시킬 수 있다.
- OSWorld의 접근법을 벤치마크했다.
- OSWorld는 일반 컴퓨터처럼 동작하는 대화형 환경으로, 에이전트가 다음 동작을 결정한다.
- GPT-4o를 활용한 스크린샷 기반 GUI 에이전트를 구성하였다
- 특정 작업(task)이 주어지면, Planner(GPT-4o)는 그 작업을 달성하기 위한 상세한 단계별 계획(plan)을 생성한다.
- 이후 각 단계에서 필요한 행동(action)과 좌표(coordinate)를 생성하며 작업을 수행한다.

- OS-Atlas-Base를 그라운딩 모듈로 사용한 GPT-4o는 아직 사람 성능에는 미치지 못하지만 다른 기법과 모델보다 뛰어난 성능을 보인다.
5 EXPERIMENTS: AGENT TASKS
5.1 EXPERIMENT SETUPS
Training details
- 데스크톱 도메인에서의 벤치마크는 상대적으로 적기 때문에, AMEX(모바일), AITZ(모바일), Mind2Web(웹)의 세 가지 데이터셋만을 사용하여 모델을 학습하였다.
- 모든 벤치마크를 사전 학습에 사용하지 않고 남겨두어 OOD(out-of-distribution) 테스트용으로 활용하기 위함이다.
- OS-Atlas-4/7B는 InternVL-2-4B와 Qwen2-VL-7B라는 서로 다른 백본 모델을 사용했다.
Evaluation Benchmarks
- 5개의 서로 다른 에이전트 벤치마크
- 모바일 에이전트:
- AndroidControl (Li 외, 2024)
- GUI-Odyssey (Lu 외, 2024a)
- 웹 에이전트:
- GUI-Act-Web (Chen 외, 2024a)
- OmniAct-Web (Kapoor 외, 2024)
- 데스크톱 (Windows 환경):
- OmniAct-Desktop
- 다른 데이터셋은 OOD 평가에 사용
- 테스트 데이터만 사용
- 모든 벤치마크를 세부 작업 단위(subtask granularity)
Settings and Baselines
제로샷 OOD 설정 (zero-shot out-of-distribution setting)
- Action Mode
- 보지 못한 작업, 도메인, 애플리케이션에 대해 모델을 제로샷(zero-shot)으로 평가
- 실제 GUI 에이전트의 사용 시나리오를 모방
지도학습 기반 파인튜닝 설정 (supervised fine-tuning setting)
- Agent Mode
- 다운스트림 작업에 맞게 모델을 파인튜닝(fine-tune)하여 특정 응용에 최적화된 에이전트를 생성하는 설정
Metrics
- Type: 액션 타입(CLICK, SCROLL 등)의 정확도 (Type Exact Match)
- Grounding: 위치(좌표) 예측 정확도
- SR (Step-wise Success Rate): action + arguments 모두 정확히 예측했을 때 성공(예시: 좌표를 정확히 클릭)
5.2 RESULTS & 5.3 ANALYSIS
- OS-Atlas
- 기존 GPT-4o, SeeClick, SoM 비교했을 때 모든 도메인과 데이터셋에서 더 좋은 성능을 보였다.
- 특히 OOD 평가(보지 못한 도메인/태스크)에서도 일반화 성능이 강화되었다.
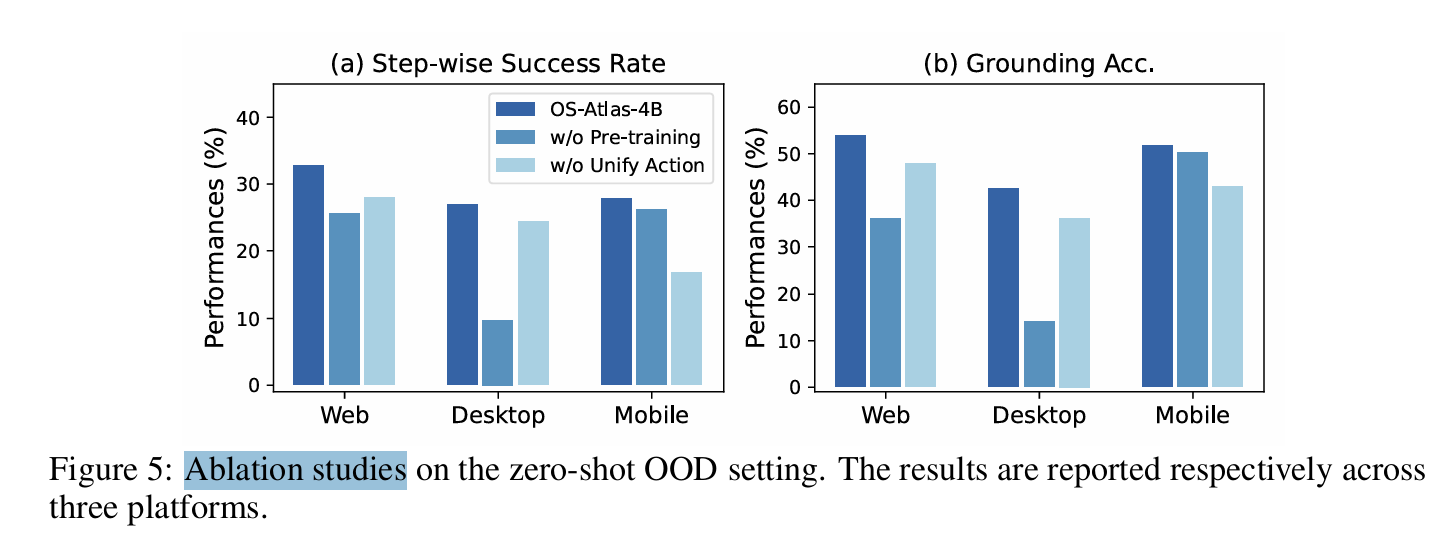
- Ablation studies
- Groundingpre-training을 생략(w/o pre-training)하면 성능 급감한다. 데이터 인프라의 중요성 입증했다
- Unify Action fine-tuning이 없이(w/o unified action) 학습하면 action로 성능 저하된다. Unify Action fine-tuning 이 필요하다.
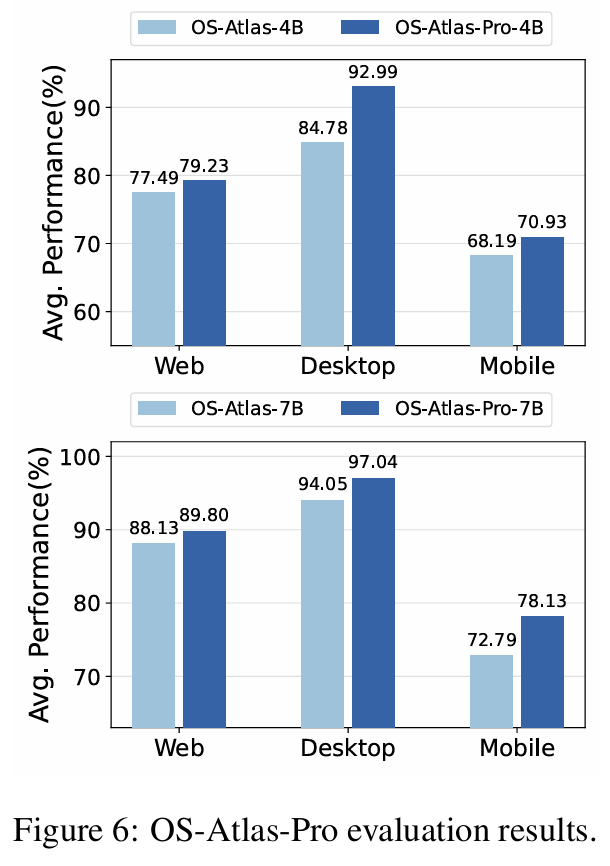
- OS-Atlas-Pro (7개 전체 데이터셋으로 학습)
- OOD 평가를 위해 제외한 데이터도 학습
- 웹/모바일/데스크톱 전반에서 SR 향상
- 실제 배포 가능성을 고려한 최종 성능 최적화 모델
6 CONCLUSION
- OS-Atlas는 GUI agents를 위한 파운데이션 액션 모델이다.(foundation action model for GUI agents)
- 제로샷 일반화 성능과 멀티태스크 파인튜닝 확장성 모두 우수함을 확인했다.
'논문 리뷰' 카테고리의 다른 글
| Griffin: Mixing Gated Linear Recurrences withLocal Attention for Efficient Language Models (0) | 2024.07.19 |
|---|---|
| [RAG] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (0) | 2024.06.14 |
| [BiGS]Pretraining Without Attention(SSM) (0) | 2024.06.10 |
| [Transformer] Attention Is All You Need (0) | 2024.04.25 |
| [GPT-2]language models are unsupervised multitask learners (0) | 2024.04.12 |